“Theorem 6: For any finite automaton (in particular, for a
McCulloch-Pitts nerve net) started at a given time \(t = 1\) with internal state \(b_1\) at that time, the event represented
by a given state existing at time \(p\)
is regular” - Stephen Cole Kleene
One of the most beautiful results in all of computability theory is
the result commonly known as Kleene’s Theorem, though its
modern formulation includes contributions by Scott and Rabin:
Theorem
Kleene’s Theorem
The following are equivalent: > >1. There is a DFA accepting
the language \(L\) >2. There is an
NFA accepting the language \(L\) >3.
\(L\) is a regular language (with a
regular expression)
We prove the equivalence of all three by showing that 1 and 2 are
equivalent (that 1→2 and 2→1), and then showing that they both imply and
are implied by 3 (specifically, that 3→2 and 1→3). ## 1→2 (if there’s a
DFA, there’s an NFA)
Since an NFA can do anything that a DFA can do and more, it is easy
to see that if there is a DFA accepting the language \(L\), then there is a nearly identical NFA
accepting the language \(L\). It’s just
a boring NFA that doesn’t use any nondeterminism or \(\epsilon\)-transitions.
2→1 (if there’s an NFA, there’s a
DFA)
The more interesting result is showing that every NFA can be
“simulated” by a DFA, so DFAs are as powerful as NFAs. The proof is
constructive, in that it explains exactly how to convert an NFA into a
DFA. This conversion process is called the Subset
Construction.
The formal definition of the subset construction is rather technical,
but the intuition is straightforward. If we feed a string \(w\) into an NFA there might be many
possible routes through the NFA spelling out \(w\) and hence we may not be able to predict
which route will be taken or while state the NFA will end up in.
However, there is a well-defined and deterministic set of states that
the NFA could end up in. That is, the set of possible
behaviours of the NFA is completely deterministic, and that can be
simulated by a DFA.
Example
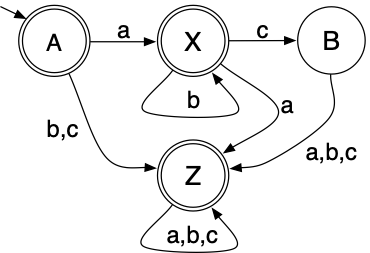
Consider the following NFA: > > >We can observe the following
properties: > >- When the NFA starts, it could choose to be in
state A or B. >- If all we know is that the NFA could be in state A
or B, and then it takes a b transition, then afterwards the
NFA could choose to be in state A, B, or D. >- If the NFA could be in
state A, B, or D, and it takes an a transition, then
afterwards it could be in state C or D. >- etc. > We can summarize
all this information with the following DFA: > > >So for
example, given a string like abba, we can run this through
the DFA, and immediately conclude that the NFA given baab
could go to state C and could go to state D; further, since going to the
accepting state C is a possibility, the NFA would accept
baab. > On the other hand, the DFA tells us that
aa can only send the NFA to state D (which is not an
accepting state), and so the NFA cannot accept aa.
Similarly, DFA tells us there is no state the NFA could end up in after
the input ab, i.e., the NFA cannot accept ab
because there is no path through the NFA corresponding to the input
ab.
Definition
Just for completeness, we give the formal definition of the subset
construction. > Given an NFA \(N = (Q_n,
\Sigma_n, \delta_n, q_{0n},F_n)\), the _ subset construction_
gives us a DFA \(D = (Q, \Sigma, \delta, q_0,
F)\) with \(L(N) = L(D)\),
defined as follows: > >- \(Q := {\cal
P}(Q_n)\) >- \(\Sigma :=
\Sigma_n\) >- \(q_0 :=
\mathsf{\epsilon{-}closure}(q_{0n})\)
>- \(F := \{\ S \in {\cal P}(Q_n)\ |\ S
\cap F_n \neq \emptyset\ \}\) >- \(\delta(S,a) = \mathsf{\epsilon{-}closure}(\ \{\
q\in Q_n\ |\ q\in\delta_n(s,a)\mathrm{\ for\ some\ } s\in S \}\
)\) > where the \(\mathsf{\epsilon{-}closure}\) of a set is
all states reachable by 0 or more \(\epsilon\) transitions from state in the
set.
3→2 (RE to NFA)
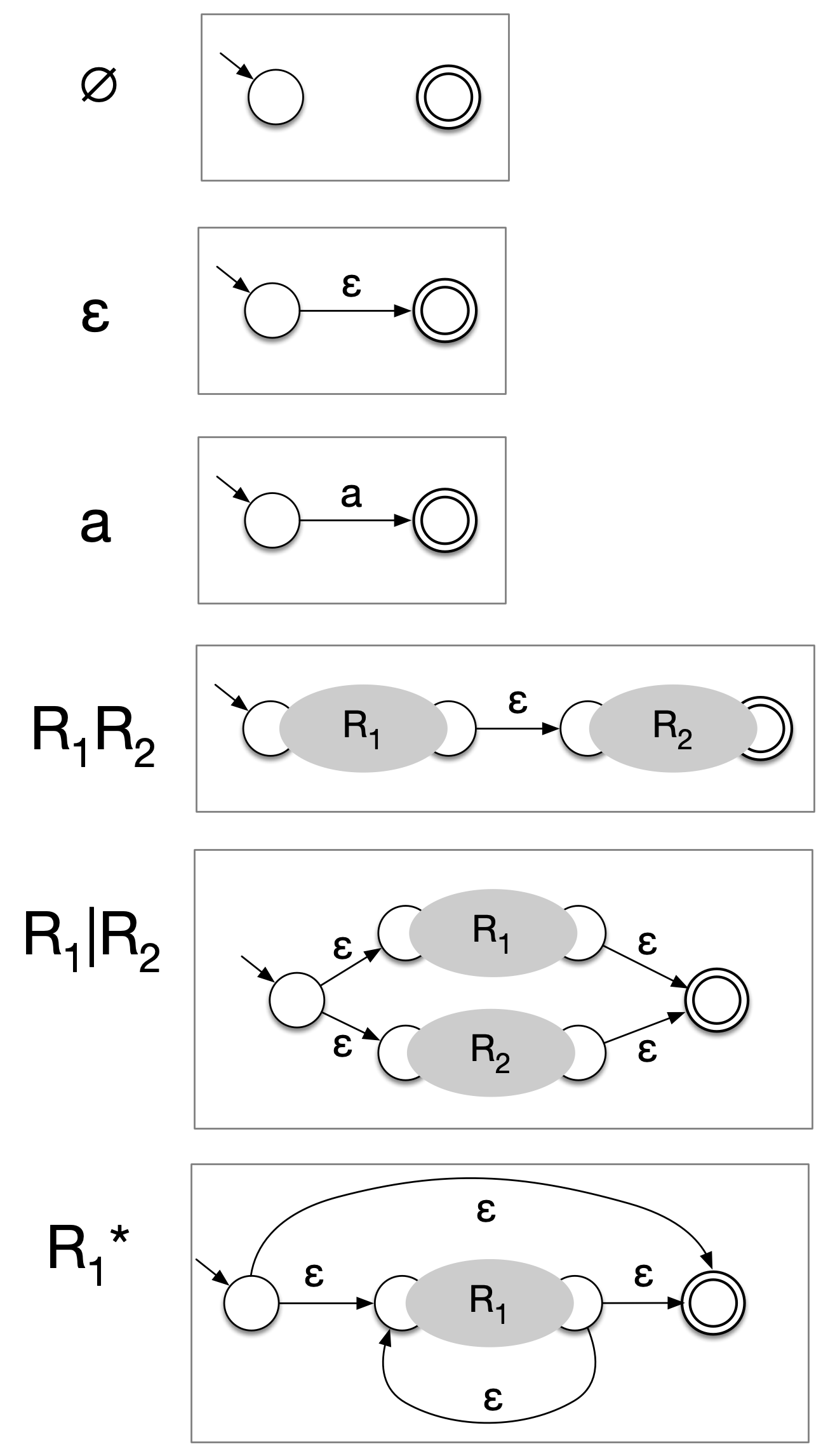
If \(L\) is regular, it can be
described using a regular expression \(R\). We can convert \(R\) into an NFA that accepts the same
language by induction/reduction on the structure of \(R\), as shown here:
RE to NFA conversion
1→3 (DFA to RE)
There are a couple of ways to convert a DFA into a regular
expression; the ideas are clever, but doing the conversion (by hand) is
admittedly tedious. Here’s we’ll show an “equation solving”
approach.
Given a state machine, the language of its state \(q\) is denoted \(L(q)\), and is defined to be the strings
that the machine would accept if we started from state \(q\) (rather than automatically
starting from the start state, as we normally would).
It follows from this definition, the language of a DFA is the same as
the language of its start state.
The language of our states are officially sets of strings, but we can
find a regular expressions for each set by solving a set of simultaneous
equations.
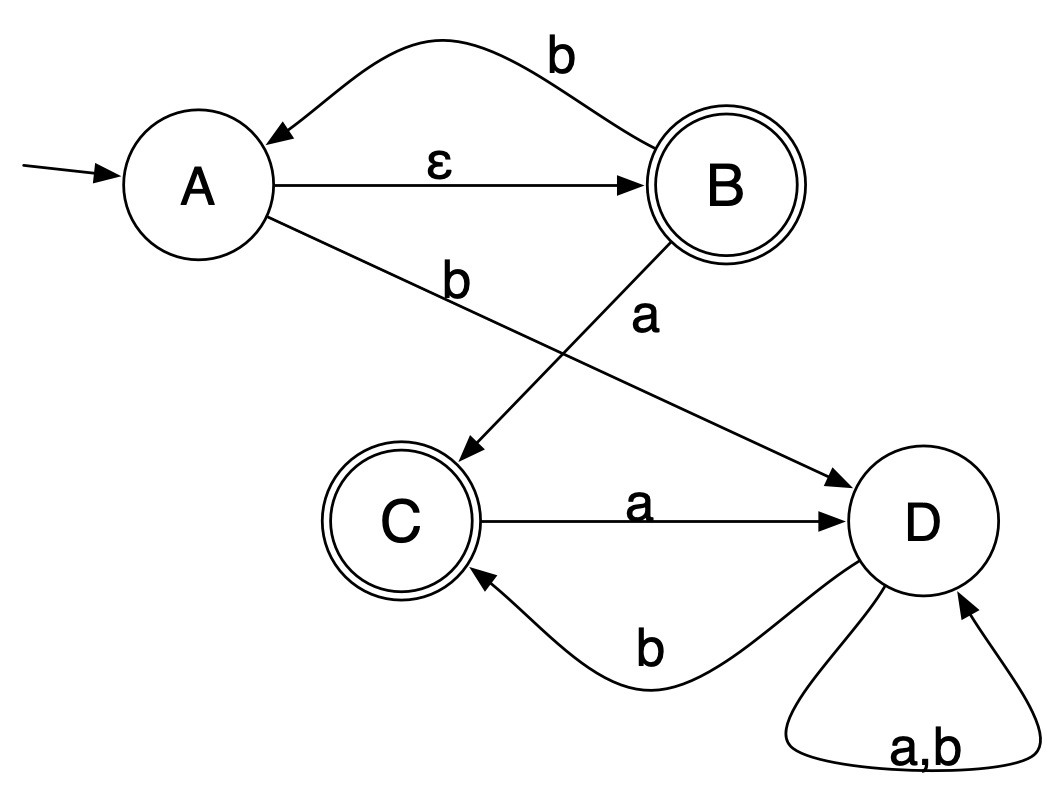
Example
Another four-state DFA
What strings are accepted starting at state A? Any string accepted
from state A either starts with a and then the rest of the
string is accepted starting from state X, or it starts with
b or c and then the rest of the string is
accepted starting from state Z. That gives us the equation >\[
>L(A) = \mathtt{a}L(X)\ |\ (\mathtt{b}|\mathtt{c})L(Z)\ |\ \epsilon.
>\] What strings are accepted starting at state X? Any string
accepted starting at X either is the empty string (since X is an
accepting state!), or starts with a and then the rest of
the string is accepted starting from state Z, or starts with
b and the rest of the string is accepted starting from
state X, or starts with c and then the rest of the string
is accepted starting from state B. That gives us the equation >\[
>L(X) = \mathtt{a}L(Z)\ |\ \mathtt{b}L(X)\ |\ \mathtt{c}L(B)\ |\
\epsilon.
>\] >What strings are accepted starting at state B? Again
we can read off that any string accepted from state B starts with an
a, b, or c and then continues
with a string accepted starting from state Z. (On the other hand, B is
not an accepting state, so its language does not include \(\epsilon\). This yields the equation:
>\[
>L(B) = (\mathtt{a}|\mathtt{b}|\mathtt{c})L(Z).
>\] >Finally, we can read off the equation >\[
>L(Z) = (\mathtt{a}|\mathtt{b}|\mathtt{c})L(Z)\ |\ \epsilon.
>\]
We can solve these equations using standard substitution techniques,
plus the following lemma:
Lemma
Arden’s Rule The (smallest) solution to a recursive
equation \[
Y=CY\ |\ D
\] is \[
Y := C^*D.
\]
Example
The same four-state DFA as
above
This automaton gave us the equations: > >1. \(L(A) = \mathtt{a}L(X)\ |\
(\mathtt{b}|\mathtt{c})L(Z)\ |\ \epsilon.\) >2. \(L(X) = \mathtt{a}L(Z)\ |\ \mathtt{b}L(X)\ |\
\mathtt{c}L(B)\ |\ \epsilon.\) >3. \(L(B) =
(\mathtt{a}|\mathtt{b}|\mathtt{c})L(Z).\) >4. \(L(Z) = (\mathtt{a}|\mathtt{b}|\mathtt{c})L(Z)\ |\
\epsilon.\) > First, (4) can be solved via Arden’s Rule to
conclude >\[
>L(Z)=(\mathtt{a}|\mathtt{b}|\mathtt{c})^*\epsilon =
(\mathtt{a}|\mathtt{b}|\mathtt{c})^*.
>\] >Substituting that into (3) yields >\[
>L(B) =
(\mathtt{a}|\mathtt{b}|\mathtt{c})^*(\mathtt{a}|\mathtt{b}|\mathtt{c}) =
(\mathtt{a}|\mathtt{b}|\mathtt{c})^+.
>\] >Substituting both of these into (2) gives us >\[
>L(X) = \mathtt{a}(\mathtt{a}|\mathtt{b}|\mathtt{c})^*\ |\
\mathtt{b}L(X)\ |\ \mathtt{c}(\mathtt{a}|\mathtt{b}|\mathtt{c})^+\ |\
\epsilon,
>\] >and rearranging and applying Arden’s Rule produces
>\[
>L(X) = \mathtt{b}^*(\mathtt{a}(\mathtt{a}|\mathtt{b}|\mathtt{c})^*\
|\ \mathtt{c}(\mathtt{a}|\mathtt{b}|\mathtt{c})^+\ |\ \epsilon).
>\] >Finally, we can substitute all these into (1) to find:
>\[
>L(A) =
\mathtt{a}\mathtt{b}^*(\mathtt{a}(\mathtt{a}|\mathtt{b}|\mathtt{c})^*\
|\ \mathtt{c}(\mathtt{a}|\mathtt{b}|\mathtt{c})^+\ |\ \epsilon)\ |\
(\mathtt{b}|\mathtt{c})(\mathtt{a}|\mathtt{b}|\mathtt{c})^*\ |\
\epsilon.
>\] >Since the language of the start state is the language
of the DFA, we have found the language accepted by the DFA (as a regular
expression).
 > >We can observe the following
properties: > >- When the NFA starts, it could choose to be in
state A or B. >- If all we know is that the NFA could be in state A
or B, and then it takes a
> >We can observe the following
properties: > >- When the NFA starts, it could choose to be in
state A or B. >- If all we know is that the NFA could be in state A
or B, and then it takes a 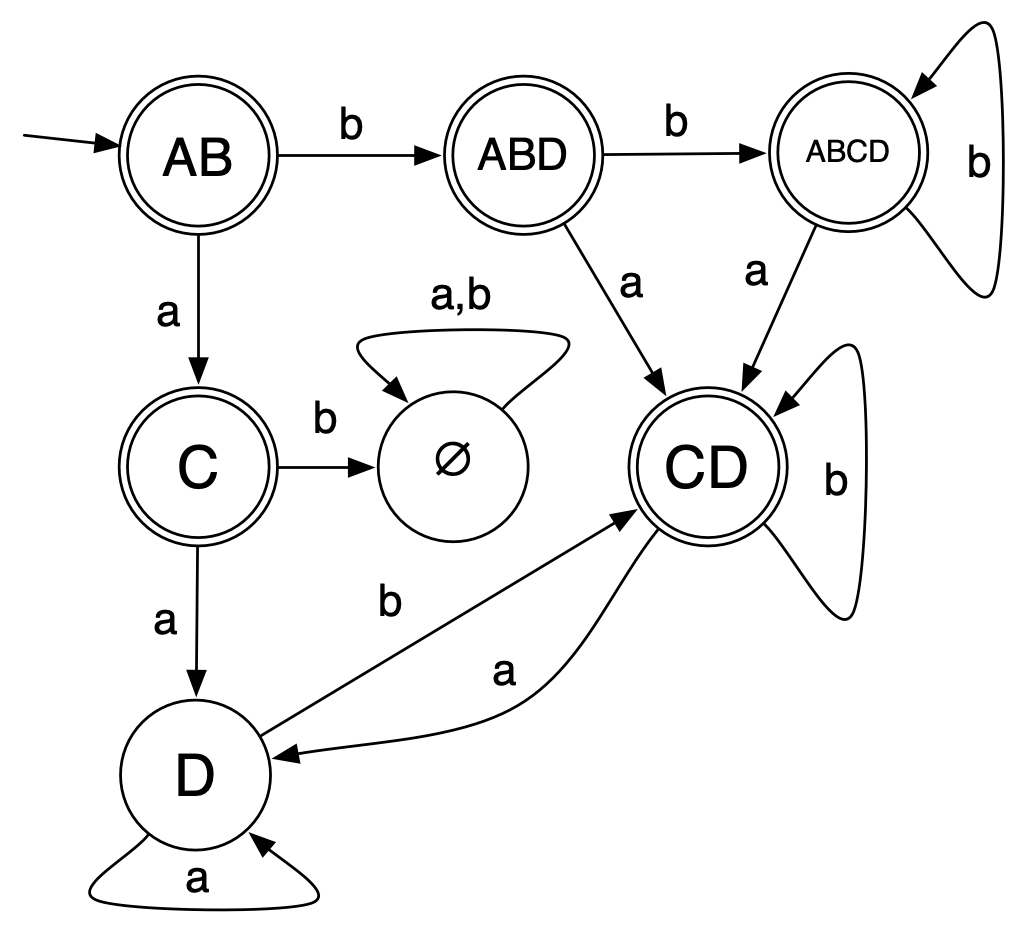 > >So for
example, given a string like
> >So for
example, given a string like